








'논문 리뷰 > GAN' 카테고리의 다른 글
| InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets 리뷰 (0) | 2022.04.07 |
|---|---|
| Generative Adversarial Nets (GAN) (0) | 2022.04.05 |
| InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets 리뷰 (0) | 2022.04.07 |
|---|---|
| Generative Adversarial Nets (GAN) (0) | 2022.04.05 |

GAN의 정보이론을 활용하는 쪽으로 확장한 InfoGAN은 완전한 un-supervised learning 방식으로 disentangled representation을 학습할 수 있습니다. 이를 위해 본 논문에서는 latent variable과 observation간에 mutual information(상호정보)을 공식화하여 목적함수에 추가하였고, 이 mutual information(상호정보)를 최대화하는 방향으로 generator가 학습되게 하였습니다.
비지도 학습은 풍부한 양의 unlabelled data로부터 가치를 추출하는 일반적인 문제로 묘사될 수 있습니다. representation learning(표현 학습)은 대표적인 비지도학습의 프레임워크로 unlabeled 데이터로부터 중요한 의미론적 특징을 쉽게 해독할 수 있는 인자들을 나타내는 representation을 학습하는 것을 목표로 합니다.
비지도 학습의 표현학습을 통해 data instance들의 핵심적인 특징을 명식적으로 나타내는 disentangleed representation을 학습할 수 있다면, 이것은 classfication 등의 dawnstream task에 유용하게 사용될 수 있습니다.
비지도 학습 연구분야의 대부분은 생성 모델링(generative modeling)이 주도하고 있습니다. 생성 모델링에서는 관측된 데이터를 합성하거나 창조하는 생성모델의 능력이 데이터에 대한 깊은 이해를 동반한다고 생각하며, 좋은 생성모델은 훈련과정에서 따로 명시하지 않더라도 스스로 disentangled representation을 학습할 것이라 생각됩니다.
본 논문에서는 2 가지의 기여점을 중심으로 서술되었습니다.
→ 기본적인 idea : 기존의 GAN은 생성모델의 input이 $$z$$ 하나 인 것에 비해 infoGAN은 $$(z,c)$$로 input에 code라는 latent variable $$c$$가 추가되고, GAN objective에 add-on을 추가해 Generator가 학습을 할 때, latent 공간($z$-space)에서 추가로 넣어준 $$c$$와 생성된 샘플 사이의 mutual information이 높아지도록 도와줍니다.
기존의 GAN의 Generator는 간단한 1D continuous latent vector $$z$$를 사전에 가정한 prior로부터 샘플링하여 그대로 사용합니다. 저자들은 이런 방식으로 $$z$$를 사용할 경우, generator의 $$z$$의 각 차원마다 분리된 개별적인 semantic feature를 학습하는게 아니라 차원들이 서로 복잡하게 얽힌 표현이 학습된다고 주장합니다.
그러나 실제로 많은 도메인의 데이터들은 자연스럽게 서로 잘 분리되어있는 의미론적 변동인자를 내재하고 있습니다.
MNIST를 예로 들자면,
숫자 종류(0~9)에 대한 변동을 포착하는 discrete latent variable, 숫자의 각도나 기울기 변동을 포착하는 continuous latent variable, 숫자의 두께 변동을 포착하는 continuous latent variable 등 서로 독립적인 세 가지의 변동인자를 각각 따로따로 학습 할 수 있으면 이상적인 결과를 나타낼 수 있습니다.
논문에서는 기존의 GAN처럼 single noise vector를 사용하지 않고, noise vector를 다음의 두 part로 분류하여 사용합니다.
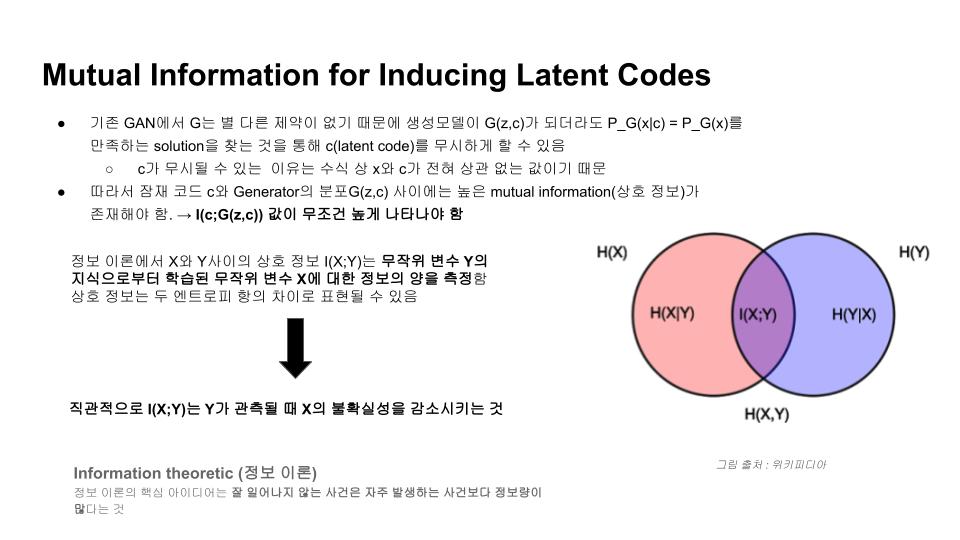
정보 이론에서 두 변수 X,Y 간에 상호정보 $$I(X;Y)$$는 다음과 같이 표현됩니다.

이것을 둘 중 하나의 변수로 관측함으로써 감소하는 나머지 변수에 대한 불확실성의 크기를 계량하는 측도로 볼 수 있습니다. 두 변수가 독립적이라면 상호정보는 $$0$$이 되고, 두 변수가 가역함수의 관계일 때 최대가 됩니다.
즉, 우리는 어떤 임의의 $$x ~ G(z,c)$$에 대해 $$P(c|x)$$가 작은 entropy를 갖는 것을 원하게 됩니다. 같은 말로 우리는 $$I(c;G(z,c))$$가 최대화 되는 방향으로 $$G(.)$$가 학습되길 원합니다.
이를 반영하는 새로운 목적함수는 다음과 같습니다.


그림에서와 같이 basis의 방향인 x축 혹은 y축으로 움직일 때 마다 규칙성이 존재하지 않고 무작위로 색이 변동되는 것을 확인할 수 있습니다. 색을 데이터에서의 어떤 의미라고 가정했을 때 이런 representation space에서 유의미한 코드를 찾기는 어려워지게 됩니다.
하지만 아래와 같이 representation space를 학습할 수 있다면 이전과 달리 각각의 basis demension이 의미를 가지고 이를 해석하기가 편리해집니다.
이렇게 representation을 학습할 때, 좀 더 좋은 성질을 갖도록 제약을 줄 수 있다면 훨씬 학습이 용이할 것이라는 것이 InfoGAN의 저자들이 말하고자 하는 바 입니다.
문제는 $I(c;G(z,c))$는 우리가 알지못하는 $c$에대한 true posterior $P(c|x)$에 대한 계산을 요구하므로 직접 최적화하는것이 어렵습니다. 대신에 VAE와 같이 $P(c|x)$를 근사하는 단순한 보조분포 $Q(c|x)$를 활용하여 상호정보에 대한 Variational Lower Bound를 구해서 간접적으로 최적화를 진행할 수 있습니다.

상호정보의 하한을 구하는 이 테크닉은 Variational Information Maximization이라고 알려져 있습니다.
이 식에서 latent code의 엔트로피인 $H(c)$는 $c$에 대해 흔한 분포를 가정할 경우, analytical한 form으로 쉽게 계산될 수 있지만, 본 논문에서는 $c$의 분포를 고정한 채 사용하여 $H(c)$를 상수로 취급하고 좌측의 항만 최적화했다고 소개하고 있습니다.
→ $I(c;G(z,c))$를 최대화 하는 대신 그것의 하한인 $L_I(G,Q)$를 최대화 하는 방식입니다. 그런데 식에서는 $c^'∼P(c|x)$와 같이 $c$의 true posterior로부터 샘플에 대한 기댓값을 구하는 파트가 존재함을 확인할 수 있습니다. 이것은

위 식을 이용하여 아래의 식의 첫번째 line을 쓸 수 있고, 우리가 모르는 True posterior 대신 흔한 분포로 가정할 수 있는 $c$의 marginal distribution $P(c)$를 사용함으로써 문제를 해결할 수 있습니다.

$L_I(G,Q)$에서 $Q$는 직접적으로 최대화될 수 있고, $G$는 reparametrization trick을 사용하여 최대화될 수 있기 때문에, 기존 GAN의 train 프로세스에 변경없이 Objective에 추가될 수 있습니다.
이렇게 유도되는 알고리즘을 Information Maximizing Generative Adversarial Networks(InfoGAN) 이라 부르며, 그것의 목적함수는 다음과 같습니다.


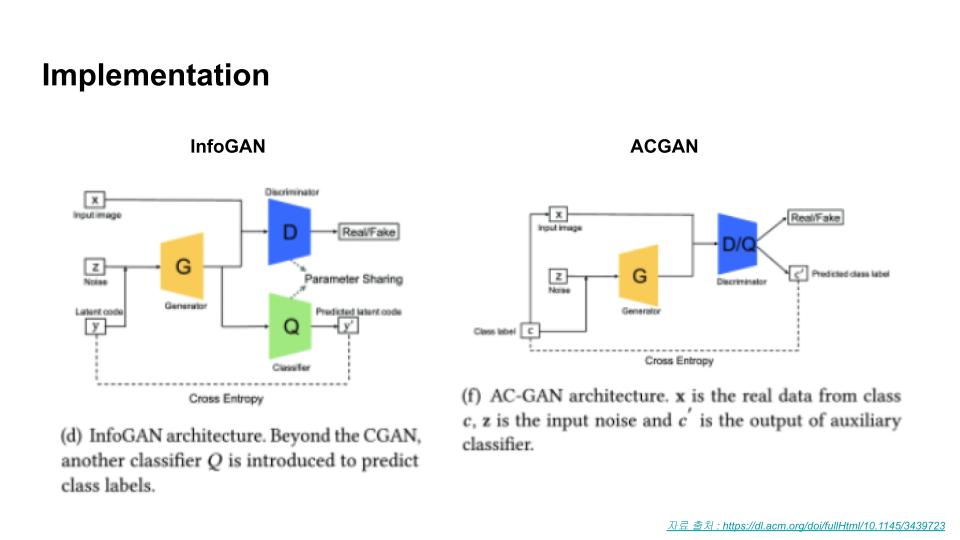
상호정보를 간접적으로 최적화하기 위해 보조 분포로써 도입한 $Q(c|x)$는 head부분을 제외한 나머지 모든 layer를 공유하게 구현했습니다. 따라서 $c$의 조건부 분포에 대한 출력을 얻게끔 하는 FC layer 하나만 추가하면 되기 때문에 추가되는 파라미터는 매우 적습니다.
→ Objective에 추가된 $L_I(G,Q)$ term을 계산하기 위해 $Q(c|x)$를 출력하는 head를 별도로 추가함 일반적인 GAN보다 목적함수의 수렴이 대부분 빠르고, 새로 추가되는 상호정보항 반영비율에 대한 하이퍼파라미터 $λ$는 튜닝이 간단하다고 합니다.

latent code $c$와 generator images $G(z,c)$간에 상호정보가 제안한 방법대로 최대화 되었는지 확인하는 실험입니다.
그림과 같이 목적함수에 $L_I(G,Q)$ term이 추가된 InfoGAN은 몇번의 에폭을 진행함에 따라 상호정보 하한이 잘 최대화된 것을 확인할 수 있습니다.
비교를 위해 동일한 네트워크 구조이지만 목적함수 $L_I(G,Q)$ term이 추가되지 않은 baseline모델을 training한 결과, 상호 정보의 하한인 $L_I(G,Q)$값이 0에 가까워지는(latent code와 생성되는 이미지간의 연관성이 없는) 방향으로 학습되는 것을 확인할 수 있습니다.
아래는 3D face 데이터에서 학습한 결과입니다.

얼굴 각도나 시선의 고도 뿐만 아니라 음영이 지는 각도 등에 대해서도 잘 나타내어집니다.

3D face 데이터와 마찬가지로 얼굴의 포즈를 학습하기도 했지만 안경의 유무나 헤어스타일, 감정 등의 변동 인자들이 잘 학습됨을 확인할 수 있습니다.
| InfoGAN paper review 발표자료 (0) | 2022.04.10 |
|---|---|
| Generative Adversarial Nets (GAN) (0) | 2022.04.05 |

*노란색 box로 쳐진 그림들이 생성된 결과 이미지*
Generative Adversarial Nets라는 제목으로 Ian Goodfellow 저자가 2014년 NIPS에서 게재된 논문이고 현재 약 42000건의 인용을 자랑할 만큼 그 당시에 획기적이였고, 생성모델의 줄기같은 논문. 현재도 많은 후속 연구들이 이어지고 있습니다.

Deep generative model들은 maximum likelihood estimation과 관련된 전략들에서 발생하는 많은 확률 연산들을 근사하는 데 발생하는 어려움과 generative context에서는 앞서 모델 사용의 큰 성공을 이끌었던 선형 활성화 함수들의 이점들을 가져오는 것의 어려움이 있었기 때문에 큰 영향을 주진 못함. 이 논문에서 소개될 새로운 generative model은 이러한 어려움을 극복해냄.
본 논문에서는 생성 모델을 추정하는 새로운 프레임 워크를 제안합니다.
adversarial nets 프레임워크의 컨셉은 ‘경쟁’으로 Generative model G는 우리가 갖고 있는 data x의 distribution을 알아내려고 노력합니다. 만약 G가 정확히 data distribution을 모사할 수 있다면 거기서 뽑은 sample은 완벽히 data와 구별할 수 없게됩니다.
한편 discriminator model D는 현재 자기가 보고 있는 sample이 training data에서 온 것(진짜)인지 혹은 G로부터 만들어진 것인 지를 구별하여 각각의 경우에 대한 확률을 estimate합니다.

D의 입장에서는 data로부터 뽑은 sample $x$는 $D(x) = 1$이 되고, $G$에 임의의 noise distribution으로부터 뽑은 input $z$를 통해 생성된 sample에 대해서는 $D(G(z))=0$ 이 되도록 합니다. 즉 $D$는 실수할 확률을 낮추기위해 노력하고 반대로 $G$는 $D$가 실수할 확률을 높이기 위해 노력하는데, 본 논문에서는 이를 “_minimax two-player game_”이라고 표현합니다.

GAN의 경쟁하는 과정을 경찰(분류 모델, 판별자)과 위조지폐범(생성 모델, 생성자) 사이의 경쟁으로 비유하면 위조지폐범은 최대한 진짜 같은 화폐를 만들어 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별하여 위조지폐범을 검거하는 것을 목표로 합니다.
이러한 경쟁하는 과정의 반복은 어느 순간 위조 지폐범이 진짜와 다를 바 없는 위조지폐를 만들 수 있고 경찰이 위조 지폐를 구별할 수 있는 확률 역시 50%로 수렴하게 됨으로써 경찰이 위조 지폐와 실제 화폐를 구분할 수 없는 상태에 이르도록 합니다.
→ GAN의 핵심 컨셉은 각각의 역할을 가진 두 모델을 통해 적대적 학습(=경쟁)을 하면서 ‘진짜같은 가짜’를 생성해내는 능력을 키워주는 것!!
논문에서는 G와 D모델을 MLP를 활용해 구성하였습니다.
Generator’s distribution $p_g$ over data $x$를 학습하기 위해 generator의 input으로 들어갈 noise variables $p_z(z)$에 대한 prior를 정의하고 data space의 맵핑을 $G(z;θg)$라 표현할 수 있습니다.
여기서 $G$는 미분 가능한 함수로써 $θg$를 파라미터로 갖는 MLP입니다.
한편, Discriminator 역시 MLP으로 $D(x;θd)$ 로 나타내며 output은 확률이기 때문에 single scalar 값으로 나타남. $D(x)$는 $x$가 $p_g$가 아닌 data distribution으로부터 왔을 확률을 나타냅니다.
이를 수식으로 정리하면 다음과 같습니다.

이 방정식을 D의 입장, G의 입장에서 각각 이해해본다면

→ 따라서 D의 입장에서 value function $V(D,G)$의 이상적인 최대값은 $0$ 이고 G의 입장에서 $V(D,G)$의 이상적인 최소값은 $-∞$ 임.
GAN은 discriminative distribution을 동시에 업데이트 하면서 학습하게 됩니다. 따라서 D는 sample distribution에서 비롯된 sample을 generative distribution으로 나온 sample로부터 판별하도록 학습합니다. 그림에서 $x, z$는 각각의 domain을 의미합니다.

이 그림이 말하고자 하는 것은 (a)처럼 real과 fake의 분포가 전혀 다르게 생긴 것을 볼 수있고, 현재 generator를 대상으로 discriminator를 학습시킨 결과가 (b)입니다.
(a)처럼 들쑥날쑥하게 확률을 판단하는 것이 아니라, 흔들리지 않고 나름 분명하게 확률을 결과로 내놓는 것을 알 수 있습니다. (a)보다 성능이 올라갔다고 표현할 수 있습니다.
어느정도 D가 학습이 이루어지면, G는 D가 구별하기 어려운 방향으로 학습을 하게되어 (c)와 같이 변하게 됩니다. 이 과정을 반복하게 되면 real과 fake가 점점 비슷해지고 결국에는 (d)와 같이 구분할 수 없게 되어 D가 확률을 0.5로 계산하게 됩니다.
→ 이 과정을 통해 진짜 이미지와 가짜 이미지를 구별할 수 없을 만한 데이터를 G가 생성해내는 것

아래를 k번 반복 (논문에서 k = 1로 실험)
이후
어떤 G에서 optimal한 D가 존재한다고 생각한다면, G가 고정된 상태에서 optimal한 D는 다음과 같습니다

D와 G를 학습시키는 criterion은 다음을 최대화 하는 것인데,

위의 식을 D(x)에 대해 편미분하고 결과값을 0이라고 두면 optimal한 D는 아래와 같이 얻어집니다

이렇게 얻은 optimal D를 원래의 목적함수 식에 대입하여 생성기 G에 대한 Virtual Training Criterion C(G)를 다음과 같이 유도할 수 있습니다.

위의 C(G)는 generator가 최소화하고자 하는 기준이 되며, 이것의 global minimum은 오직 $p_g = p_{data}$ 일때 달성되고 그 점에서의 C(G)값은 log4가 됩니다.
정보 엔트로피는 하나의 확률분포가 갖는 불확실성(놀람의 정도) 혹은 정보량을 정량적으로 계산할 수 있도록 하는 개념을 나타내고 교차 엔트로피는 두 가지 확률 분포가 얼마나 비슷한지를 수리적으로 나타내는 개념입니다.
G와 D가 충분한 capacity를 가지며, algorithm 1의 각 스텝에서 discriminator가 주어진 G에 대해 최적점에 도달하는게 가능함과 동시에 $$p_g$$가 위에서 제시한 criterion을 향상시키도록 업데이트 되는 한, $$p_g$$는 $$p_data$$에 수렴합니다.

GAN 구현 코드
G는 objective function을 최소화, D는 최대화시키며 각 네트워크를 학습시킨다는 것은 알겠는데, 서로 적대적으로 최대/최소화를 하며 optimal point에 도달할 수 있을까?
→ 답은 이미 나와 있다. 실제로 generator sample의 distribution과 real data distribution 사이의 간격을 최소화시켜서 0에 가깝게 만들기 때문에!!
즉, pg = pdata에 대한 global optimum을 가진다. → 이걸 objective function을 통해 증명해보자.


D의 max값을 찾아서 이제 변수가 아니기 때문에 max=C(G)로 두고(새로운 함수. D 빠짐) 식을 다시 정리하면 위와 같다. 단순하게 구한 D를 대입한 결과이다.

두 번째 명제는 pg=pdata인 경우에 C(G)가 global minimum을 가진다는 것이다. 즉, 우리가 원하는, 직관적으로 생각하는 이상적인 결과(pg=pdata)가 수식적으로도 global optimum이라는 것을 증명하는 것이다.

KL, JSD: 간단히 말해서 두 분포 사이의 거리를 의미한다. 거리이기 때문에 최소값은 0이고, 양수이다.
⇒ 최종 식 -log4+JSD를 통해서, minmax problem을 차례대로 풀어 global optimum을 찾으면, generator가 만드는 pg이 pdata와 정확히 일치하도록 할 수 있다는 것을 알 수 있다!
⇒ 결국 generator로부터 뽑은 sample을 discriminator가 실제 데이터와 구별할 수 없게 되었다는 것이다. = 우리가 원하는 결과임
| InfoGAN paper review 발표자료 (0) | 2022.04.10 |
|---|---|
| InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets 리뷰 (0) | 2022.04.07 |