Convolution
Image Data
- 먼저 이미지를 정형 데이터화 하는 방법을 생각해보자. 정형 데이터화 라는 말은 컴퓨터로 식별가능한 형태로 데이터를 변환하는 것을 의미한다. 예를 들어, 남자/여자라는 내요잉 있으면, 남자를 0 여자를 1로 하겠다와 같은 약속을 정형화한다고 한다. 임지ㅣ는 픽셀 단위로 구성이 되어 있고, 각 픽셀은 RGB 값으로 구성되어 있다. 즉 아주 자즉안 색이 담긴 네모 상자가 여러개가 모여 이미지가 되며, 색은 R(빨강), G(초록), B(파랑)의 강도의 합으로 표현할 수 있다. 이미지를 정형 데이터화 하는 것 방법 중 하나는 흑백 이미지의 경우 '가로x세로'에 흑색의 강도가 들어간 배열로, 컬러이미지의 경우 '가로x세로x3'의 배열로 나타낼 수 있으며 마지막 3에는 각각 R,G,B의 강도의 값으로 구성할 수 있다.

Convolutional Layer (합성곱 층)
Convolutional Layer가 왜 필요한가?

- 다음과 같은 3x3 이미지를 고려해보자. 우리가 일반 딥러닝 구조로 이미지를 분석한다는 것은 3x3 배열을 오른쪽 처럼 펼쳐서(Flattening)하여 각 픽셀에 가중치를 곱하여 은닉층으로 연산 결과를 전달하는 것과 같다. 이미지의 특성상 각 픽셀 간에 밀접한 상관 관계를 가지고 있을텐데, flattening해서 분석하면 데이터의 공간적 구조를 무시한다는 것을 쉽게 알 수 있다. 이미지 데이터의 공간적인 특성을 유지하는 것이 convolutional layer의 등장에 큰 동기가 되었다.
Convolution (합성곱) 이란?
Convolution은 두 함수 $(f,g)$를 이용해서 한 함수$(f)$의 모양이 나머지 함수 (g)에 의해 모양이 수정된 제 3의 함수 $(f * g)$를 생성해주는 연산자로 통계, 컴퓨터 비전, 자연어 처리, 이미지 처리, 신호 처리 등 다양한 분야에서 이용되는 방법이다. Convolution의 정의는 다음과 같다.
$\left(f*g\right)(t)=\int_{-\infty}^{\infty}f(\tau)g(t-\tau)d\tau$
Convolution의 정의를 그대로 이해하면 y축 기준 좌우가 반전이 된 함수 $g$를 우측으로 t만큼 이동한 함수$g(t-\tau)$와 $f(\tau)$를 곱해진 함수의 적분이다. 다움 두 함수 $f,g$를 고려해보자.

함수 $f,g$는 $f(t)=I\left(t\in[0,1]\right)$,$g(t)=tI\left(t\in[0,1]\right)$입니다. 먼저 $t = 3$인 경우를 생각해보자.

빨간선 $f$는 고정된 것과 파란선 g를 y축 대칭시킨뒤 우측으로 3만큼 이동한 것을 볼 수있는데, 이 때 두 하숨를 곱한 것이 적분 대상이 되며 초록띠와 대응된다. 초록띠와 x축으로 둘러 쌓인 면적이 0이므로 $t=0$의 convolution은 0이 된다.
$t = 0.5$ 일때는 다음과 같다.

초록띠와 x축으로 둘러 쌓인 면적은 0.25로 $t = 0.5$에서 convolution 결과이다. t를 $-\infty$ 부터 $\infty$ 까지 순차적으로 살펴보면 다음과 같다.
최상단의 그림은 함수 g가 이동하면서 연산의 적분 대상함수의 모습을 가운데는 convolution 결과가 순차적으로 생성되는 과정을, 마지막은 $f * g$의 결과이다.
추가적으로 Cross-correlation이 있다. Cross-correlation은
$(f*g)(t)\int_{-\infty}^{\infty}f(\tau)g(t+\tau)$
이다. g에서 y축 반전을 거치지 않는 것이 convolution과의 차이이다. 비교해서 살펴보면 아래와 같다.

Convolutional Layer의 연산법은 정확하게 cross-correlation이다. 하지만 CNN에서는 가중치를 학습하기 때문에 convolution과 cross-correlation을 정확히 구분 할 필요가 없다.
Convolutional Layer(합성곱 층)
Convolutional layer는 아래 그림과 같이 빨간 상자를 sliding window 방식으로 가중치와 입력값을 곱한 값에 활성함수를 취하여 은닉층으로 넘겨준다.

Convolution layer는 사람이 실제로 보는 것을 우측의 파란 3x3 픽셀 이라고 했을떄, 전체를 인시갛는 것이 아니라, 일부분을 빨간색 상자로 투영하고 그를 우측의 주황색 수용 영역에 연결되어 복합적으로 해석하는 것을 모방한 것이다.
Convolutional Latyer 계산 방법 개요

위 그림의 좌측은 흑백 이미지의 픽셀 값이고, 우측은 좌측의 이미지를 투영하여 convolution(합성곱 연산)을 하는것으로 필터(filter) 혹은 커널 (kernel) 또는 윈도우 (window)라고 부른다.
딥러닝 프레임워크 관점에서 말하면 픽셀 값은 입력 값(input)이 되고, 필터 값은 가중치(weight)가 된다.
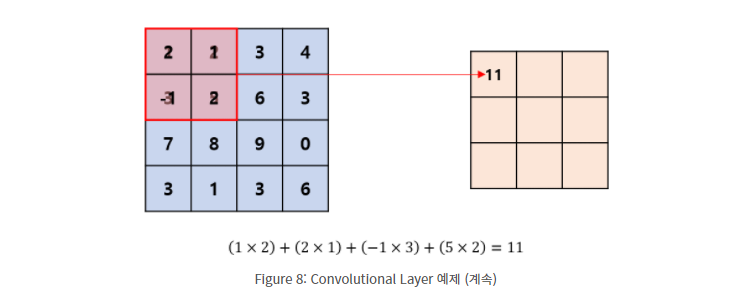
이미지 좌상단에 이미지와 필터를 포개놓고 대응되는 숫자끼리 곱한 뒤, 모든 숫자를 더해주면 된다.
이어서 필터를 sliding window 방식으로 이동해가며 합성곱 연산을 수행하면 된다.

합성곱 연산의 결과를 특성(feature) 라고 부른다. 위 예제 기준으로 만약 이미지를 Flattening한다면 16개 가중치를 학습해야 될 것이다. 보는것처럼 convolutional layer를 도입하여 학습할 가중치가 4개로 줄었고 컴퓨터 연산의 수를 획기적으로 감소시켰다.
가중치에는 편의(bias)를 더해준것처럼 Convolutional Later에서도 편향을 더해주기도 한다.

Stride (스트라이드)
필터를 입력데이터나 특성에 적용할 때 움직이는 간격을 스트라이드(Stride) 라고 한다.

Padding (패딩)
패딩은 반복적으로 합성곱 연산을 적용했을 때 특성의 행렬의 크기가 작아짐을 방지하는 것과 이미지의 모서리 부분의 정보손실을 줄이고자 이미지 주변을 0으로 채워넣는 방법이다.


1d convolution
1x1 Convolution 에는 크게 세가지 장점이 있다.
- Channel 수 조절
Convolution Layer를 사요앟여 Custom Model을 구성할 경우, Channel 수는 하이퍼파라미터이기 때문에 우리가 직접 결정해주어야 한다. 대부분은 논문을 참조하지만 그렇지 않은 경우 특성에 맞게 결정한다.
이 부분에서 1x1 Conv의 장점인 Channel 수를 우리가 원하는 만큼 결정 할 수 있다. 하지만 Convolution 연산에서는 특히 충분히 큰 크기의 channel 수를 사용하고자 할 때 문제가 발생한다. 왜냐하면 그만큼 파라미터 수가 급격히 증가하기 때문이다. 하지만 1x1 Convolution을 사용하면 효율저긍로 모델을 구성함과 동시에 만족할만한 성능을 얻을 수 있다.
- 계산량 감소
여기서 파라미터 수는 주로 결과값 크기를 의미한다. 밑 그림에서 (28*28)을 제거해야 진정한 의미의 파라미터 수라고 말할 수 있다. 하지만 편의를 위해 파라미터 수라고 언급하도록 하겠다.

위 그림처럼 Channel 수 조절은 직접저긍로 계산량 감소로 이어지게 되어 네트워크를 구성할 때 좀 더 깊게 구성할 수 있도록 도움을 준다. 특히 위처럼 Channel 수를 줄였다가 다시 늘이는 부분을 Bottle neck 구조라고 표현하기도 한다. 파라미터 수가 많으면 아무리 보유하고 있는 GPU나 RAM이 좋아도 감당하기 힘드니 충분히 고려해볼만한 방법이다.
- 비선형성
GoogLeNet을 포함하여 구글팀의 수많은 고민이 포함되어 적용된 Inception 계통의 다양한 model version을 공부하면, 많은 수의 1x1 Conv를 사용했다는 것을 알 수있다. 이때 ReLU를 지속적으로 사용하여 모델 비선형성을 증가시켜 준다. ReLU 사용 목적 중 하나는 모델의 비선형성을 더해주기 위함도 있다. 비선형성이 증가한다는 것은 그만큼 복잡한 패턴을 좀 더 잘 인식할 수 있게 된다는 의미와 비슷하다.
AlexNet

AlexNet은 일부가 Max-pooling layer가 적용된 5개의 convolution layer와 3개의 fully-connected layer로 이루어져 있다.
AlexNet의 구조에 적용된 특징
- ReLU Nonlinearity
활성화 함수로 ReLU 를 적용시켰다.
4층의 CNN으로 CIFAR-10을 학습시켰을 때 ReLU가 tanh보다 6배 빠르다고 한다. - Traingng on Multiple GPUs
network를 2개의 GPU로 나누어 학습시켰다. 120만개의 data를 학습시키기 위한 network은 하나의 GPU로 부족하다고 설명했다. 2개의 GPU로 나누어 학습시키니 top-1 error와 top-5 error가 1.7% 1.2%씩 감소되고 학습속도가 빨라졌다고 한다. - Local Response Nrmalization(LRN)
LRN은 generalization을 목적으로한다. 논문에서는 LRN을 측면 억제(later inhibition)의 형태로 구현한다고 나와있다. AlexNet 이후 현대의 CNN에서는 LRN 대신 batch normalization 기법이 쓰인다. - Overlapping Pooling
Overlapping pooling을 통해서 overfit을 방지하고 top-1와 top-5 error를 각각 0.4% 0.3% 낮추었다고 한다. - data augmentation
- Dropout
VGGNet


ILSVRC 2012에서 우승한 AlexNet(8 layer) 과 비교하여 VGG(16-19 layer)는 2배가량 깊어졌다.
VGGNet은 항상 이웃픽셀을 포함할 수 있는 가장 작은 3x3 필터만 사용한다.
이렇게 작은 필터를 유지해 주고 주기적으로 Pooling을 수행하며 전체 네트워크를 구성한다.
GoogLeNet

이 모델의 주요 특징은 연산을 하는데 소모하는 자원의 사용 효율이 개선되었다는 것이다. 즉, 정교한 설계 덕에 네트워크의 depth와 width를 늘려도 연산량이 증가하지 않고 유지된다는 뜻이다. 이때 Google팀에서는 성능을 최적화하기 위해서 Hebbian principle과 multi-scale processing을 적용하였고, 이 구조를 GoogLeNet이라 부른다고 한다. GoogLeNet은 22개의 layer를 가지며, 코드네임은 Inception이다.
GoogLeNet에 영향을 많이 끼친 논문중 Network in Network는 신경망의 표현력을 높이기 위해 제안된 접근법이다. 이 방법은 1x1 Convolutional layer가 추가되며, ReLU activation이 뒤따른다. 이 때 1x1 Convolutional layer는 두 가지 목적으로 사용된다.
병목현상을 제거하기 위한 차원 축소와 네트워크 크기 제한이다.



ResNet
딥러닝에서 neural networks가 깊어질수록 성능은 더 좋지만 train이 어렵다는 것은 알려진 사실이다. 그래서 이 논문에서는 residual(잔차)를 이용한 잔차학습(residual learning framework)를 이용해서 깊은 신경망에서도 training이 쉽게 이뤄질 수 있다는 것을 보이고 방법론으로 제시했다.



DenseNet
DenseNet은 ResNet과 Pre-Activation ResNet보다 적은 파라미터 수로 더 높은 성능을 가진 모델이다. DensNet은 모든 레이어의 피쳐맵을 연결한다. 이전 레이어의 피쳐맵을 그 이후의 모든 레이어의 피쳐맵에 연결한다 연결할 때는 ResNet과 다르게 덧셈이 아니라 concatenate(연결)을 수행한다. 따라서 연결할 때는 피쳐맵 크기가 동일해야 한다. 피쳐맵을 계속해서 연결하면 채널 수가 많아질 수 있기 때문에, 각 레이어의 피쳐맵은 채널 수는 굉장히 작은 값을 사용합니다.


이렇게 연결하면 어떤 장점이 있을까?
-
- strong gradeint flow와 information flow를 갖는다. 이는 기울기 소실 문제를 완하하고 feature reuse 효과가 있다.
-
- 파라미터수와 연산량이 적어진다.

참고자료
(https://hwiyong.tistory.com/45)
(https://kangbk0120.github.io/articles/2018-01/inception-googlenet-review)
(https://codebaragi23.github.io/machine%20learning/3.-ResNet-paper-review/)
'네이버 부스트캠프 AI Tech' 카테고리의 다른 글
| 부스트캠프 AI Tech 2기 - 10 Generative Model (0) | 2022.04.05 |
|---|---|
| 부스트캠프 AI Tech 2기 - Transformer (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 - 7 Optimization (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 - 7 CrossValidation (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 - 6 DL Basic, Visualization (0) | 2022.04.05 |