통계학
데이터를 보고 확률분포 가정하기.
- 확률 분포를 가정하는 방법 : 히스토그램을 통해 모양을 관찰
- 데이터가 2개의 값 ( 0 또는 1 ) 만 가지는 경우 -> 베르누이분포
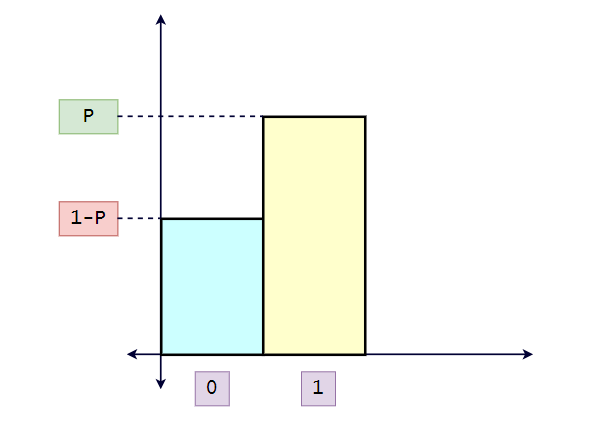
- 데이터가 n개의 이산적인 값을 가지는 경우 -> **카테고리분포**

- 데이터가 (0,1) 사이에서 값을 가지는 경우 -> **베타분포**

- 데이터가 0 이상의 값을 가지는 경우 -> **감마분포, 로그정규분포 등**

- 데이터가 실수 전체에서 값을 가지는 경우 -> **정규분포, 라플라스분포 등**

- 기계적으로 확률분포를 가정해서는 안 되며, 데이터를 생성하는 원리를 먼저 고려하는것이 원칙
중심극한정리(Central Limit Thorem)
- 동일한 확률 분포를 가진 독립 확률 변수 n개의 평균의 분포는 n개가 커짐에 따라
모집단 분포의 모양에 관계없이 정규분포와 가까워지는 정리

