Conditional Generative Model
1. Conditional generative model
1.1 Conditional generative model

서로 다른 두 도메인을 translation 한다.! -> 하나의 정보(조건)이 주어졌으므로 condition 이라 칭함.

기본적인 Generative Model은 영상이나 샘플은 생성할 수는 있었지만 조작은 할 수 없었다. 생성을 더 유용하게 하기 위 해서는 어떤 형태로든 유저의 의도가 반영할 수 있다면 무수히 많은 응용 가능성이 생긴다. 그런 생성 모델 방식을 Conditional generative model 이라고 한다.

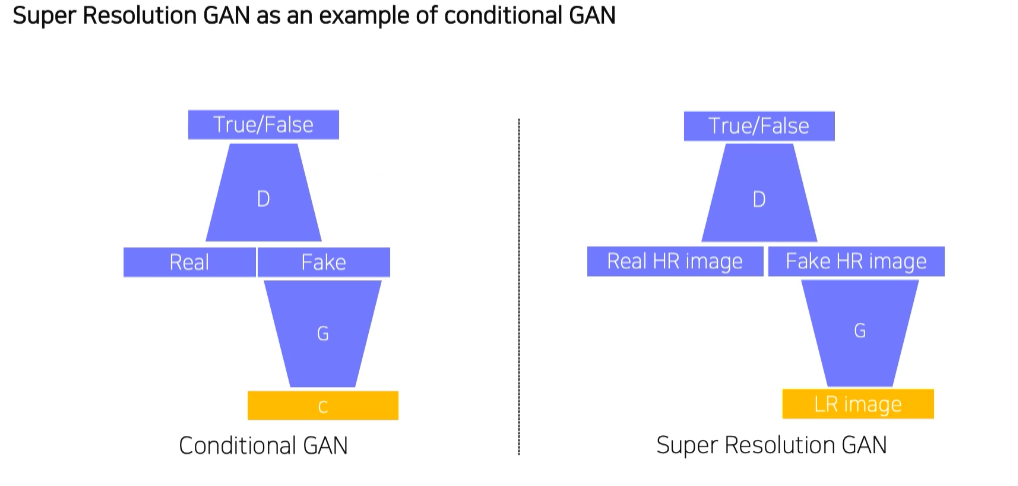
Low quality audio을 high quality audio로 높혀주는 것도 Conditional Generative model의 일종이다.



1.2 Conditional GAN and image translation

1.3 Example : Super resolution





2. Image translation GANs
2.1 Pix2Pix
Task definition

Loss function of Pix2Pix

Total loss (GAN loss + (L1 loss = MAE loss)) 를 쓰는 이유
y 가 ground Truth 인데 x 라는 입력을 넣었을때 기대하고 있는 출력 페어를 가지고 있는 데이터에 대해 학습을 진행한다.(supervised learning) 이 경우에, GAN Loss 만 사용한다면 입력된 두개의 페어(x,y)를 직접 비교하지않고 독립적으로 Discriminator 해서 real 이냐 fake 이냐에 대해서만 판별을 한다. 따라서 입력이 무엇이 들어와도 y와 직접 비교하지않기 때문에 GAN만 사용한다면 y와 비슷한 결과를 만들어 낼 수 없다. 따라서 L1 Loss 를 사용해서 기대하는 결과인 y 와 비슷한 영상이 나오고 GAN Loss 를 이용하여 reality 한 영상을 만들 수 있게 해준다.
GAN만으로 학습하기엔 굉장히 불안정하고 어렵기 때문에 학습이 조금 더 안정적으로 이루어질 수 있도록 보조하는 역할도 한다.

2.2 CycleGAN

지금까지의 Pix2Pix는 supervised learning 기법을 사용했기 떄문에 pairwise data가 필요하다.
하지만 pairwise data 를 항상 얻는게 어렵기 때문에 Unpaired data 데이터를 사용해서 X 와 Y 의 대응관계가 없이 data set으로만 주어졌을때 활용하는 방법에 대해서 고민했고 해결책으로 CycleGAN 이 제시되었다.

CycleGAN은 도메인간의 non-pairwise datasets 으로 translation 이 가능하도록 하게 해줌.
Loss funtion of CycleGAN

X -> Y 스타일로 가는 방향과 Y -> X 스타일로 가는 방향을 동시에 학습하여 모델링을 한다.
GAN loss in CycleGAN

If we sloely use GAN loss

GAN Loss만 사용할 경우 (Mode Collapese issue) input에 상관없이 하나의 output 만 계속 출력하는 형태로 학습한다. -> GAN Loss 기준에선 좋은 Loss를 갖게 된다!
Solution: Cycle-consistency loss to preserve contents

content 보존을 위한 Loss. x를 input으로 G를 활용해 생성한 y^가 F를 활용해 x^를 생성했을때 x와 x^가 비슷하도록 학습.
2.3 Perceptual loss


high quality output 을 얻기 위한 Loss
GAN is hard to train

pretrained 된 visual perception들이 인간의 visual perception과 유사한 측면이 발견됨. ( 사람의 눈과 비슷한 역할 )

Perceptual loss 를 사용하면 GAN을 사용하지 않고도 Loss 하나만을 추가함으로서 쉽게 style transfer를 할 수 있는 generator를 학습시킬 수 있다.

Image Transform Net : input image가 주어지면 하나의 style로 transformed 을 해준다.
Loss network(Fix된 VGG16) : image classification network -> feature 추출

Feature Reconstruction Loss
input x 에서부터 y^ 생성한다.
y^이 의도한 바로 transform이 되기 위해 VGG 를 사용해 feature 를 추출하고 backpropagation 을 해서 중간 transform을 하려는 f를 학습한다.
Transformed image가 input x에 포함되어 있었던 Content 정보를 유지하고 있는지 권장해주는(?) Loss가 바로 Feature reconstruction loss 이다.
Content Target 은 원본 x 를 입력으로 넣어주고, 이후 VGG 를 통과하여 feature 를 추출한다. 그 다음 마찬가지로 transform된 이미지에 대해서도 feature를 추출한다. 이 두가지를 비교해서 Loss 를 분해한다.
이 두개를 분해할땐 L2 Loss 를 통해 backpropagation 을 이용하여 y를 업데이트 할 수 있게끔 해준다.

Feature reconstruction loss는 Pre-trained 모델 Hidden Layers에서 출력이미지와 원본이미지의 두 Feature space 을 추출하여 연산하며, 두 Feature space 간의 Euclidean distance를 나타낸다. 해당 Loss의 특징은 아래 그림과 같이 이미지 전반적인 구조(Overall spatial structure)를 유지하며, 그 외 색상이나 질감에 대한 특징은 보존하지 않는다.
Style reconstruction loss

변환하고 싶은 style image 를 style target 으로 입력한다.
style target 과 transformed image 를 VGG에 입력으로 넣어줘서 feature를 추출한다.

Style reconstruction loss는 바로 위에 설명했던 Feature reconstruction loss와 정반대로, 이미지의 전반적인 구조보다는 원본이미지의 색상이나 질감을 출력이미지가 표현할 수 있도록 만드는데 기여하는 Loss 이다.
Gram Matrices
이미지 전반에 걸친 통계적 특성을 담기 위함.
gram matrix란 flatten feature maps 간 계산한 covariance matrix이다.
이미지 데이터의 style은 CNN 모델의 feature map과 feature map의 correlation(gram matrix)으로 사전 정의한다. 결국 기존 그림의 gram matrix와 새로운 그림의 gram matrix의 loss 차를 최소화 시켜 새로운 그림에 기존 그림의 style을 입히겠다는 의미를 갖는 것이다.
'네이버 부스트캠프 AI Tech' 카테고리의 다른 글
| 부스트캠프 AI Tech 2기 - fewshot learning (0) | 2022.04.05 |
|---|---|
| 부스트캠프 AI Tech 2기 CV - 3D Understanding (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 CV - panoptic segmenation and landmark localization (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 CV - Object Detection (0) | 2022.04.05 |
| 부스트캠프 AI Tech 2기 CV - Segmentation Overview (0) | 2022.04.05 |


















 - ROI Pooling layer
- ROI Pooling layer









































































 {: height="500"}
{: height="500"} {: height="500"}
{: height="500"} {: height="500"}
{: height="500"}